![[rss feed 圖案]](/~ckhung/i/rss.png)
從網頁產生書單
有時候我們需要的資料, 其實已經以網頁格式存在, 但想進一步去蕪存菁, 略過 html 的標籤等等, 只抓出關鍵欄位放入試算表 (建議用 .csv 格式), 資料庫 (變成一串 insert 指令), 或是程式中陣列的初始值。 具有 web 2.0 概念的 AJAX 程式, 特別有機會需要做這類事情。 當然, 這篇講義不談 javascript; 甚至 perl 也不是重點; regexp 才是重點。
請用 wget 指令抓下 Astronomy Book List 網頁 (或稍微處理過的 本地映射, 下詳), 並用 less 或 vim 檢視其原始碼。 以下試著抓出列表裡面所有書籍的:
- 頁數 (例如: "265 Pages", "288 Pages", ...)
- 年月 (例如: "Nov-94", "Sep-92", ...)
- 價格 (例如: "$23.07", "$12.00", "$11.96", ...)
- 作者 (例如: "Peter L. Manly", "Chet Raymo", "Stephen W. Hawking", "Peter J. Duffett-Smith", ...)
- 作者的姓 (例如: "Manly", "Raymo", "Hawking", "Duffett-Smith", ...)
- 代號 (例如: "0521433606", "0671766066", "0553346148", ...)
- 圖檔檔名 (例如: "astro13.gif", "astro2.gif", "astro28.gif", ...)
- 書名 (例如: "The 20-Cm Schmidt-Cassegrain Telescope", "365 Starry Nights: An Introduction to Astronomy for Every Night of the Year", "A Brief History of Time: From the Big Bang to Black Holes", ...)
頁數可以這樣抓: perl -ne 'print "$1\n" if /(\d+\s+Pages)/' astrobooks.htm
請專注在底色強調的部分; 其他部分都是固定的句型, 不需要理解,
只要照抄就可以了。 以下其他的例子將省略完整指令,
只列出底色強調部分, 也就是 regexp 的部分。 至於列印字串 print "..."
的內容, 當然也可以視需要自行修改。 其中的 $1 表示 「從 regexp 當中,
取出第一對小括弧所比對到的內容」。 又, 從這個例子看到: 遇到空格處,
建議用 \s+ (「1 個, 2 個, ... 任意個空白類字元」)
因為有時候用眼睛看, 很難判斷到底有幾個空格, 到底是空格還是
tab。
年月可以這樣抓: \b([A-Z][a-z][a-z]-\d\d)\b
價格可以這樣抓: (\$\d+\.\d+) 因為
$ 「一列的結尾處」 和 . 「任何一字元」 都是 regexp 的特殊字元,
所以需要用 "\" 取消它們的特殊意義。
要抓作者, 第一步先想到這樣: 「by 之後的一整串, 一直到逗點為止」,
於是寫成: \bby\s+(.*), 所謂 "一整串",
就是 「任意字元出現任意次」, 也就是 .*。 可是這樣會抓到太多。
在這裡, 我們看到 regexp 的一個特性: 貪婪 (greedy) --
只要還有機會滿足比對條件, 就盡量吃, 用力吃。 這時需要用 「不貪婪的
*?」 像這樣: \bby\s+(.*?), 這裡的 *?
意思和 * 一樣, 都是 「前面的東西可以出現 0 次, 1 次, 2 次, ...
任意次」; 唯一的差別是: * 很貪婪, 吃越多越好; *? 很客氣,
很知足, 越早結束越好。
同樣地, 要抓作者的姓, 本來也希望用 .* 來略過名字的部分,
但又不希望略得過頭了, 所以改用 [客氣的, 知足的] .*?: \bby\s+.*?([-\w]+),
當然, regexp 通常沒有唯一的答案。 以 「作者完整姓名」 為例,
也可以這樣寫: \bby\s+([^,]*), 其中
[^,]* 可以翻譯成: 「到第一個逗點為止」。 只有少數 regexp 引擎像
perl 一樣支援 *? 在其他不支援此符號的 regexp 引擎中,
「除了...之外」 這一招很好用。
代號可以這樣抓: ASIN\/(\d+)\/sbsoftware 因為 / 是搜尋的分隔符號,
所以必須用 \ 取消它的特殊意義。 另一個方法是改用其他的分隔符號,
例如改用 #, 不過這時候就必須加上個 "m" 表示搜尋, 像這樣: perl
-ne 'print "$1\n" if m#ASIN/(\d+)/sbsoftware#'
astrobooks.htm
圖檔檔名可以這樣抓: img\s+src="(.*?)"
書名可以這樣抓: font
size=\+1>(.*?)<
每一題做出來後, 也請將輸出 pipe 給 wc, 像這樣:
perl -ne ... | wc 數數看各抓到幾筆資料。
總共有 42 本書; 每本書都有作者, 年月, 價格; 其中 30 本有圖檔,
33 本有頁數, 39 本有代號。 怎麼會只有 39 本有代號?
沒代號怎麼讓消費者下訂單啊? 怪怪的...
進入 vim, 先設定 「高亮度顯示搜尋結果」 :set hlsearch
然後稍微修改抓代號的 regexp, 並搜尋:
ASIN\/[0-9]\+\/sbsoftware
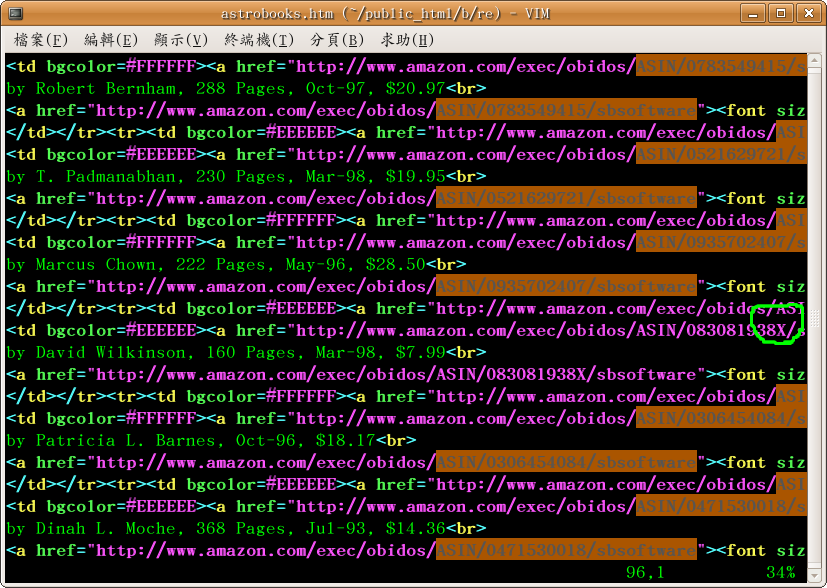
會發現有些書的代號以 X 結尾, 如下圖。
用 less 搜尋也可以, 搜尋指令變成 ASIN/[0-9]+/sbsoftware;
不過 vim 的圖比較漂亮, 所以這裡貼 vim 的圖 :-)
因此, 抓代號的 regexp 改成才對:
ASIN/(\d+\w?)/sbsoftware
(以下較進階, 可略過, 不影響其他章節的理解)
如果想要一次抓足所有欄位, 把它變成一個 csv 檔呢? (comma separated values, 用逗點分隔的純文字檔, 任何試算表軟體可讀)
第一步, 先認識 perl 的 paragraph mode: 忽略純文字檔的換列,
把好幾列當作一個單位來處理, 直到一個空白列才結束, 當做下一個單位。
不過對於 windows/dos 格式的檔案, paragraph mode 好像不太靈光。
所以我已事先用 perl -pe 's/\015//' astrobooks.htm > x; mv
x astrobooks.htm 把原檔案每列尾巴的 \n\r 改成只剩 \n
變成標準的 unix 格式純文字檔。 請拿這個修改過的 本地映射 來認識何謂 paragraph mode: perl
-000 -ne 'print "$1\n" if /(.{10})/' astrobooks.htm 效果是:
以空白列分隔的區塊為單位 (總共只有八塊) 印出每塊最前面十個字元。
關於 perl 的 paragraph mode 及更多相關資訊, 詳見 perlrun 手冊。
如果把 (.{10}) 改成 (.*) 會發現每個區塊只剩最前面一列。 因為 .
無法比對換列字元。 沒關係, 改用 ... if /(.*)/s ... 這個結尾的 s 意思是: 令 .
可以比對到探列字元。 可以這樣檢驗結果: perl -000 -ne 'print
"$1\n" if /(.*)/s' astrobooks.htm |
diff - astrobooks.htm 應該看出:
處理完的結果與原檔案幾乎一模一樣, 只差多了八個換列。 關於 s 的用法,
詳見 perlre 手冊, 並在手冊內搜尋 "single"。
所以我們沿著 <tr> 出現的地方 (表格的換列)
插入換列字元, 像這樣: perl -pe
's#</tr><tr>#</tr>\n\n<tr>#' astrobooks.htm
| less 每本書之間是不是有空白列分開了呢?
接下來就可以把一本書的所有資料視為一筆資料,
一口氣把圖片, 代號, 書名, 作者寫入同一個 regexp。
注意其中好幾處都用 .*? [客氣地, 知足地] 擷取或略過不特定長像的一段字串:
perl -pe
's#</tr><tr>#</tr>\n\n<tr>#' astrobooks.htm
| perl -000 -ne 'print "$2, $1, $4, $3\n" if
m#<img\s+src="(.*?)".*?ASIN/(\d+\w?)/.*?font
size=\+1>(.*?)<.*?\bby\s+(.*?),#s'
且慢, 請把輸出 pipe 給 wc, 會發現原先的 42 筆資料,
現在只剩 30 筆。 那是因為並非每筆資料都有圖片。 所以改成這樣: perl -pe
's#</tr><tr>#</tr>\n\n<tr>#' astrobooks.htm
| perl -000 -ne 'print "$3, $2, $5, $4\n" if
m#(<img\s+src="(.*?)"|no picture).*?ASIN/(\d+\w?)/.*?font
size=\+1>(.*?)<.*?\bby\s+(.*?),#s'
就是在原本的抓圖檔名部分外面包上 (...|no
picture), 並且記得調整列印時的 regexp 代號
(因為多了一對小括弧)。
其他欄位就當作作業囉。
- 本頁最新版網址: https://frdm.cyut.edu.tw/~ckhung/b/re/booklist.php; 您所看到的版本: February 14 2012 10:32:25.
- 作者: 朝陽科技大學 資訊管理系 洪朝貴
- 寶貝你我的地球, 請 減少列印, 多用背面, 丟棄時做垃圾分類。
- 本文件以 Creative Commons Attribution-ShareAlike License 或以 Free Document License 方式公開授權大眾自由複製/修改/散佈。