電腦怎麼存文字檔?
這個練習的後半部用 Linux 底下的 mlterm 及 gedit 來做會比較方便。 如果在 Windows 底下, 建議用 XLiveCD 啟動 X Server, 並用 ssh 遠端登入老師的 Linux 伺服器操作。
ASCII 碼
請在 Linux 的終端機 (例如 mlterm) 底下建立一個文字檔, 叫做 quote.txt 好了, 內容像這樣:
The future is what you do with the software,
not what you paid for the software
-- Mark Shuttleworth, Ubuntu Sponsor
5/2/2005 http://www.zdnet.com.au/news/software/0,2000061733,39190252,00.htm
建議前面不要放多餘的空白, 等一下研究起來比較簡單。
在 shell 底下, 把它印出來看: cat quote.txt
沒有問題。 實際上存在電腦裡面, 每個字母, 數字, 或標點符號各佔一個
byte。 我們將它用電腦儲存的方式印出來看: od -t x1 <
quote.txt | less 在 less 的操作介面下, 請按以下鍵: /
20| 0a 並按 ENTER 鍵, 搜尋
"空格後面跟著 20" 或 "空格後面跟著 0a" 得到類似這樣的結果:
0000000 54 68 65 20 66 75 74 75 72 65 20 69 73 20 77 68
0000020 61 74 20 79 6f 75 20 64 6f 20 77 69 74 68 20 74
0000040 68 65 20 73 6f 66 74 77 61 72 65 2c 0a 6e 6f 74
0000060 20 77 68 61 74 20 79 6f 75 20 70 61 69 64 20 66
0000100 6f 72 20 74 68 65 20 73 6f 66 74 77 61 72 65 0a
0000120 2d 2d 20 4d 61 72 6b 20 53 68 75 74 74 6c 65 77
0000140 6f 72 74 68 2c 20 55 62 75 6e 74 75 20 53 70 6f
0000160 6e 73 6f 72 0a 35 2f 32 2f 32 30 30 35 20 68 74
0000200 74 70 3a 2f 2f 77 77 77 2e 7a 64 6e 65 74 2e 63
0000220 6f 6d 2e 61 75 2f 6e 65 77 73 2f 73 6f 66 74 77
0000240 61 72 65 2f 30 2c 32 30 30 30 30 36 31 37 33 33
0000260 2c 33 39 31 39 30 32 35 32 2c 30 30 2e 0a
0000276
這些就是 ASCII code: 0x0a 是換列 (LineFeed); 0x20 是空格; 0x30 到 0x39 是數字; 0x41 到 0x5a 是大寫字母; 0x61 到 0x7a 是小寫字母。
中文
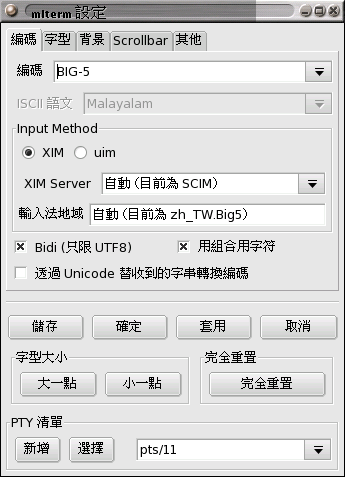 那麼中文字在電腦裡面怎麼存呢? 一個 byte
最多只能表達 256 種不同的值, 顯然無法表達所有的中文。 所以有
big5 編碼, 用兩個
byte 表達一個中文字。 請在 mlterm 底下按 ctrl-滑鼠右鍵,
叫出設定對話框, 確認目前選擇的編碼是 big5, 如右圖。
那麼中文字在電腦裡面怎麼存呢? 一個 byte
最多只能表達 256 種不同的值, 顯然無法表達所有的中文。 所以有
big5 編碼, 用兩個
byte 表達一個中文字。 請在 mlterm 底下按 ctrl-滑鼠右鍵,
叫出設定對話框, 確認目前選擇的編碼是 big5, 如右圖。
首先產生一個文字檔, 內含 「中文」 二字: echo '中文' >
tw.txt 接著印出來看看: cat tw.txt 顯示 "中文"
二字, 一切正常。 一樣, 對電腦來說, 它仍舊不過是一堆數字而已: 下
od -t x1 < tw.txt 看到 5 個 bytes: a4 a4 a4
e5 0a 最後一個還是換列字元; 前面的 a4 a4 及 a4 e5 分別正是
「中」 「文」 二字的 big5 編碼。
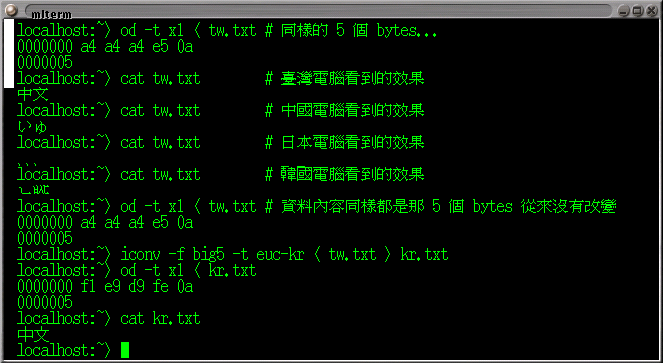
麻煩的是, 不是只有臺灣用中文。 我們的左鄰右舍都用中文; 但他們的電腦, 面對相同的數字, 卻各有不同的解釋。 請對照上圖, 依序操作以下指令。 井字號後面是註解, 本來敲不敲進去都無所謂; 但這裡因為切換編碼的關係, 建議剪貼時將它略過, 小心不要複製到, 以免螢幕上出現亂碼。 (我的圖是因為每次都多切換一次回 big5, 註解才正常顯示)
- 用上箭頭把先前的指令
cat tw.txt叫出來, 但暫時不要按ENTER。 先在 mlterm 的設定對話框當中, 把編碼改成 EUC-CN (GB2312), 並記得按 「套用」, 再按ENTER。 這個意思是要求 mlterm 模擬中國電腦, 用 gb2312 編碼去解釋/顯示它看到的資料。 - 重複上面步驟, 但這次把編碼改成 SJIS, 模擬日本電腦用 shift-jis 編碼去解釋/顯示它看到的資料。
- 重複上面步驟, 但這次把編碼改成 EUC-KR, 模擬韓國電腦用 euc-kr 編碼去解釋/顯示它看到的資料。
- 再把
od -t x1 < tw.txt指令叫出來, 確認一下資料內容從來都沒有改變過。
並不是上述這些國家的電腦無法顯示 「中文」 這兩個字, 只是在每個國家, 要儲存/顯示同樣的這兩個字, 用的 字元編碼 (character encoding) 都不同。 例如在韓國電腦裡面, 「中文」 這兩個字的編碼分別是 f1 e9 與 d9 fe。
- 先用轉換編碼的工具 iconv 把 tw.txt 的內容轉成韓文的編碼, 存入
kr.txt 檔案中:
iconv -f big5 -t euc-kr < tw.txt > kr.txt - 看一下 「中文」 這兩個字在韓國電腦裡面的編碼:
od -t x1 < kr.txt - 記得現在 mlterm 的編碼是 euc-kr, 也就是正在模擬韓國電腦。
下指令
cat kr.txt果然正確顯示 "中文"。 注意字形不太一樣, 因為剛才模擬的是臺灣環境, 用臺灣字形; 現在模擬的是韓國環境, 用韓國字形。
瀏覽器選單上的 「檢視」==> 「語系及字元編碼」 的功用, 就是在決定用那一種方式來解釋網頁資料: 同樣的兩個 bytes, 在正簡中文或日韓文電腦系統中, 各代表不同的字。
Unicode: 解決資訊地球村的書同文問題
那麼如果一篇文章, 一篇網頁裡面, 同時需要出現數種語言呢?
這是今日資訊地球村必須面對, 非常實際的問題。 於是出現了 unicode,
一個包含全世界所有主要語言的字元集。 例如 「中」 的 unicode
代碼是十六進位的 4E2D, 而 「文」 的代碼則是十六進位的 6587。
又如英文字母 「A」 的代碼是十六進位的 0041, 換列字元是 000a,
都和它們的 ASCII 代碼一樣, 只不過各變成 2 個 bytes。 請下指令:
echo '中文' | iconv -f big5 -t unicode | od -t x1 或
iconv -f big5 -t unicode < tw.txt | od -t x1
接下來我們在命令列底下打 bc 進入無限精準度計算機,
將 「中文」 的 unicode 轉成十進位。 進入 bc 之後,
沒有任何提示符號。 別怕, 先試一下 3*5-4
(每個指令打完要按 Enter) 果然出現答案。 再打 ibase=16
表示要用 16 進位輸入。 然後輸入剛才查到的 16 進位數字, 例如
4E2D (A-F 要大寫!), 按 Enter 之後出現 20013。
同樣的方法查出十六進位的 6587 其實是十進位的 25991。
隨便找一個 html 檔 用純文字檔案編輯器打開, 敲入兩個 html
entities 如下: 中 文
存檔後再用瀏覽器打開來看, 就出現剛才查詢的字元, 跟本例的 ### - �
### 一樣。 現在請用 「檢視」==> 「語系及字元編碼」 選取
shift-jis 或 euc-kr 或甚至是俄語希伯來語等等完全不相關的語言。
再在網頁裡面搜尋 ### 找到上面的字串, 會發現不論編碼怎麼變,
它依舊是中文。 最後請檢視本頁原始碼, 看看它的寫法。 這裡我們看到
html entity 加上 unicode 的另一個功用:
不管使用者用什麼編碼去解釋一篇網頁,
用這種方式顯示的文字都不會改變。
utf8: Unicode 的一種高效率編碼方式
但是如果要像上面這樣每個字元都用 2-6 個 bytes 來表示, 就很不經濟了。 例如那些原本用 ASCII 碼就可以表達的檔案 (像是程式原始碼之類的), 如果改用 unicode 存, 檔案大小馬上變成兩倍大。 比較好的方式是用短碼表達常用的字元; 長碼表達比較少用的字元。 就像 摩斯電碼 一樣, "e", "i", "t" 之類最常出現的字母, 分配到最短的編碼, 讓整份文件變短。 utf8 正是為此而設計的。 它不過就是將 unicode 的原始編碼重新調整, 使得每個 ASCII 字元只佔一個 byte, 每個中文字元佔 3 個 bytes, ... 等等。 其他諸如 utf7, utf16, ucs2, uc4, ... 等等編碼, 也分別各是 unicode 的不同編碼方式, 基本上都能完整表達 unicode 字集; 但 utf8 是最常用的 unicode 編碼。
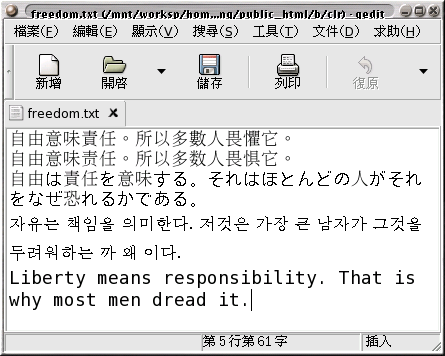 以下我們將編輯一個文字檔, 採用 utf8 編碼,
所以可以在一份文件裡面同時顯示多國語言。 請開啟 gedit 之類, 支援
utf8 的編輯軟體。 就拿蕭伯納的 這句名言
作例子吧: "Liberty means responsibility. That is why most men dread
it." 前往 Babel Fish
翻譯服務, 把英文貼上, 並選取 "English to Chinese-Traditional",
最後按 Translate 翻譯, 出現中文 "自由意味責任。所以多數人畏懼它。"
確認一下這篇網頁的編碼是 utf8: 可以查看 「檢視」==>
「語系及字元編碼」, 也可以檢視頁面原始碼,
注意最上面那一段裡有一句提到 charset 及 UTF-8。 把翻譯結果剪貼到
gedit 裡面。 再繼續從本頁選 "English to Chinese-Simple",
同樣將翻譯結果剪貼到 gedit 裡面。
當然也可以翻譯成日韓俄文或希臘文等等, 不過翻得好不好就不知道了。
存檔並在 mlterm 底下將它 cat 出來看。 (記得要調整編碼) 也可以用
以下我們將編輯一個文字檔, 採用 utf8 編碼,
所以可以在一份文件裡面同時顯示多國語言。 請開啟 gedit 之類, 支援
utf8 的編輯軟體。 就拿蕭伯納的 這句名言
作例子吧: "Liberty means responsibility. That is why most men dread
it." 前往 Babel Fish
翻譯服務, 把英文貼上, 並選取 "English to Chinese-Traditional",
最後按 Translate 翻譯, 出現中文 "自由意味責任。所以多數人畏懼它。"
確認一下這篇網頁的編碼是 utf8: 可以查看 「檢視」==>
「語系及字元編碼」, 也可以檢視頁面原始碼,
注意最上面那一段裡有一句提到 charset 及 UTF-8。 把翻譯結果剪貼到
gedit 裡面。 再繼續從本頁選 "English to Chinese-Simple",
同樣將翻譯結果剪貼到 gedit 裡面。
當然也可以翻譯成日韓俄文或希臘文等等, 不過翻得好不好就不知道了。
存檔並在 mlterm 底下將它 cat 出來看。 (記得要調整編碼) 也可以用
od -x 觀察它的編碼, 並與 我的檔案 比較。
有許多網站提供 utf8 查詢 unicode 的服務, 例如中文的 全字庫 及英文的 fileformat 與 slayeroffice 等等。 文件採用 utf8 編碼是未來的趨勢。 事實上多數的新興軟體, 例如 blog 與 wiki, 都已採用 utf8。 世界, 果然又要變得更平一點了...
一點理論
character set 是字元集; encoding 是編碼。 對於 big5 (或其他專為單一語言設計的簡單碼) 來說, 這兩者可說是同一回事; 但對於 unicode 來說, 就很明顯地可以看出這是兩回事。 unicode 是 character set; 而 utf8 是它的眾多 encoding 之一, 最多人用的那種。 不過由於歷史因素, 很多文件/軟體選單仍舊將兩者混用。 多數時候並不至於造成混淆與困擾。
- 本頁最新版網址: https://frdm.cyut.edu.tw/~ckhung/b/clr/cs-enc.php; 您所看到的版本: February 14 2012 10:02:29.
- 作者: 朝陽科技大學 資訊管理系 洪朝貴
- 寶貝你我的地球, 請 減少列印, 多用背面, 丟棄時做垃圾分類。
- 本文件以 Creative Commons Attribution-ShareAlike License 或以 Free Document License 方式公開授權大眾自由複製/修改/散佈。
HTML 檔
uni2ascii 的使用範例: ascii2uni -Y < a.html >
b.html